Projektübersicht
Master-Arbeit
Einführung
In meiner Masterarbeit erforsche ich das volle Potenzial von KI-gestützten Chatbots. Ich bin der Meinung, dass wir keine allgemeine Künstliche Intelligenz (AGI) benötigen, sondern vielmehr spezialisierte KI-Module, die effizient miteinander interagieren.
Durch die Kombination mehrerer KI-Technologien – darunter Speech-to-Text (STT), Large Language Models (LLM) und Text-to-Speech (TTS) – können KI-Agenten entwickelt werden, mit denen Nutzer direkt sprechen können. Ziel meiner Masterarbeit ist es, eine Pipeline zu entwerfen und zu implementieren, die diese KI-Module sowie weitere Komponenten integriert, um möglichst menschenähnliche Gesprächspartner für verschiedene VR-Szenarien zu erschaffen.
Projektinfos
| Projekt | Master-Arbeit |
| Team | Solo |
| Beginn | 2023 |
| Geplanter Abschluss | Februar 2025 |
| Umstände | Studium - Abschluss |
| Umfang | 45k Wörter |
| Status | WIP |
Thema ist das entwiclen einer KI pipline zur Ermöglichung von modularen Chatbots mit Langzeitgedächtnis.

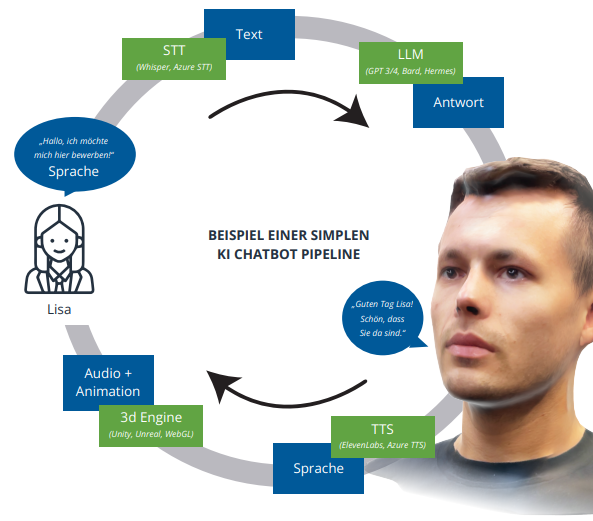
Diese Grafik zeigt eine vereinfachte übersicht über die einzelnen Schritte in einer KI-Pipeline.
Idee
Oftmals existiert eine bahnbrechende Technologie lange, bevor sie tatsächlich weitreichende Veränderungen mit sich bringt. Ein gutes Beispiel ist GPT-3, das bereits seit 2020 verfügbar war und in Fachkreisen für Aufsehen sorgte – unter anderem dadurch, dass es sogar ein wissenschaftliches Paper über sich selbst verfasste. Doch erst mit der Einführung von ChatGPT im Jahr 2022, einer zugänglichen Webplattform, die die Interaktion mit GPT-3 für jedermann ermöglichte, kam es zu einem regelrechten KI-Boom.
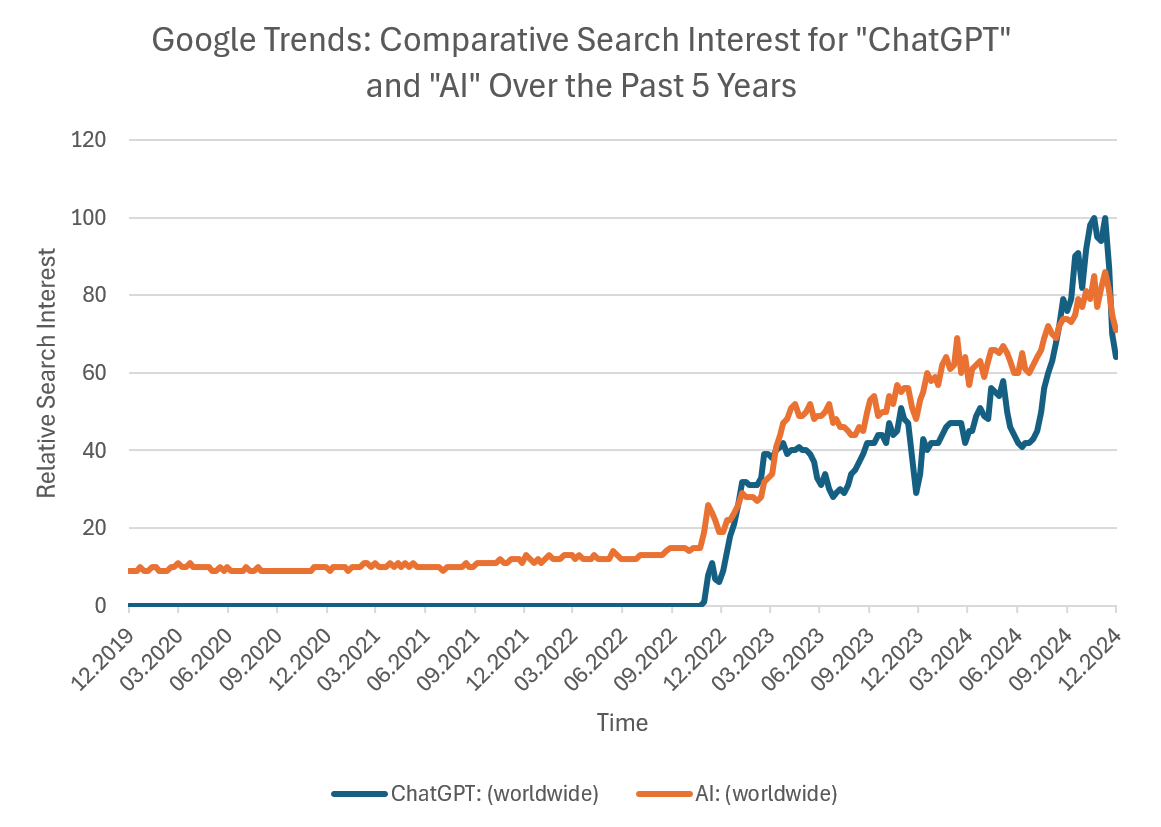
Google-Suchindex: AI vs. ChatGPT
Diese Grafik zeigt den Google-Suchindex für die Begriffe "AI" und "ChatGPT". Sie veranschaulicht, dass ChatGPT den KI-Boom ausgelöst hat.
Ich bin überzeugt, dass es in dieser Richtung noch viele weitere Durchbrüche geben wird. Besonders im Bereich der KI-Assistenten erwarte ich, dass wir in den kommenden Jahren alle auf sie angewiesen sein werden – und sie aktiv nutzen werden. Ein kleines Gedankenspiel: Die Technologie existiert bereits, um die Stimme eines Kindes zu klonen und damit automatisierte Betrugsanrufe an Eltern zu tätigen. Sobald solche Methoden regelmäßig vorkommen (oder KI-generierte Anrufe allgemein zu einem Problem werden), wird der Bedarf an KI-Assistenten steigen, die solche Anrufe erkennen und abwehren können.
GPT hat bereits die Art und Weise, wie Texte geschrieben werden, revolutioniert. Ich bin überzeugt, dass dasselbe auch mit sprachbasierten Interaktionen passieren wird.
Vorarbeit
Bereits vor meiner Masterarbeit habe ich mich mit der Idee beschäftigt, Mensch-Maschine-Interaktionen durch KI zu ersetzen. Während meines Usability-Unterrichts entwickelten wir einen Flowchart für die Interaktion mit einer textbasierten Kaffeemaschine. Dabei fragte ich mich: Warum sollte das nicht auch mit Künstlicher Intelligenz funktionieren? Alles, was benötigt wird, sind gut durchdachte Prompts und eine KI, die Befehle ausführen kann.
Dies führte zu meinem ersten Prototypen einer KI-gestützten Kaffeemaschine. Doch schnell wurde mir klar, dass dieses Konzept weit über einfache Maschinensteuerung hinausgehen könnte.
Der nächste Schritt war, eine Simulation zu entwickeln, die einen echten Nutzen bietet – beispielsweise das Training für Bewerbungsgespräche. Zufällig hatte ich bereits 3D-Scans meines Kollegen „Thom“ angefertigt. Über Nacht übertrug ich das Konzept der KI-Kaffeemaschine in Unity und ersetzte sie durch ein digitales Abbild meines Kollegen. Das Ergebnis war der „Digitale Thomas“ – ein schwebender Kopf, der ein Bewerbungsszenario durchspielt. Dieses Experiment wurde zur Hauptinspiration für meine Masterarbeit.
Doch dieser erste Prototyp zeigte mir auch die Grenzen des Ansatzes: Ich benötigte eine stabilere und modularere Architektur, um interaktivere Chatbots zu entwickeln. Warum sich nur auf eine KI-Kaffeemaschine mit Entscheidungsbäumen oder einen Bewerbungstrainer beschränken? Die Möglichkeiten sind nahezu unbegrenzt.
Recherche
Die Literaturrecherche ergab viele interessante Erkenntnisse über klassische Chatbots – einige davon fanden Anwendung in der finalen KI-Pipeline. Grundsätzlich lassen sich Chatbots in zwei Kategorien einteilen:
- Hedonische Chatbots: Diese sollen möglichst menschenähnlich mit den Nutzern interagieren und natürlich wirkende Gespräche führen.
- Pragmatische Chatbots: Diese verfolgen ein klares Ziel, z. B. die Bestellung eines Kaffees, und reduzieren die Konversation auf das Nötigste.
Frühere Chatbot-Technologien waren stark durch Keyword-Erkennung eingeschränkt. Dank standardisierter Sprachen wie der Artificial Intelligence Markup Language (AIML) konnten pragmatische Chatbots – etwa Amazon Alexa – bereits sehr effizient arbeiten. Doch wirklich hedonische Chatbots existierten bis vor Kurzem nur als Konzept und scheiterten am Turing-Test.
Bereits früh gab es komplexe Chatbot-Systeme wie ELIZA, die ein menschliches Gespräch simulieren konnten. Doch diese Systeme versagten, sobald tiefere Gespräche über ein bestimmtes Thema geführt wurden. Entscheidungsbäume (Decision Trees) führten schnell zu einer exponentiellen Zunahme der Komplexität, wodurch themenübergreifende Dialoge kaum umsetzbar waren.
Umsetzung
Large Language Models (LLMs) ermöglichen es, Antworten nicht nur auf Basis eines vordefinierten Entscheidungsbaums, gespeicherter Variablen oder Keyword-Erkennung zu generieren. Stattdessen formulieren sie Antworten anhand ihrer Trainingsdaten und des aktuellen Kontexts. Die Größe dieses Kontextes variiert je nach Modell, ist jedoch in der Regel groß genug, um zusammenhängende Gespräche zu führen und sinnvolle Antworten zu generieren.
Hier entsteht jedoch ein zentrales Problem: Während klassische Chatbots versuchen, die „richtige“ Antwort aus einer festen Auswahl zu wählen (z. B. durch eine Rückfrage wie „Können Sie genauer erklären, um welches Problem es sich handelt?“), generiert ein LLM immer eine Antwort – selbst wenn diese faktisch falsch ist. Dieses Phänomen wird als Halluzination bezeichnet. Im Grunde könnte man sagen, dass jede Antwort eines LLM halluziniert ist – allerdings sind moderne Modelle dank umfangreicher Trainingsdaten und optimierter Architekturen oft erstaunlich präzise.
Das Training eines Modells darauf, „Ich weiß es nicht“ als Antwort zu geben, ist herausfordernd. Schließlich soll das Modell möglichst hilfreiche Antworten liefern, ohne bei jeder Anfrage unsicher zu sein. Gleichzeitig ist es essenziell, Fehlinformationen zu minimieren.
Die KI-Pipeline
Um dieses Problem zu lösen, habe ich ein modulares System entwickelt, das verschiedene Technologien kombiniert. Die folgende Pipeline bildet die Grundlage für meine Chatbots:
- INPUT: Verarbeitung von Texteingaben oder Sprache
- STT (Speech-to-Text): Umwandlung gesprochener Sprache in Text
- Process User Input: Überprüfung auf direkte Benutzerbefehle und deren Ausführung
- Context Craft: Erstellung des Kontexts für das LLM, bestehend aus:
- Prompt
- Chatverlauf
- Verfügbare Befehle für den Bot
- Relevante Dokumente
- Informationen über die Umgebung (z. B. Objekte, die der Nutzer hält)
- LLM (Large Language Model): Das Herzstück, das eine kohärente und sinnvolle Antwort generieren soll
- Process AI Answer: Prüfung, ob der Bot Befehle ausgeführt oder Dokumente angefordert hat
- TTS (Text-to-Speech): Umwandlung der generierten Antwort in gesprochene Sprache, inklusive kontextabhängiger Betonung
- OUTPUT: Generierung einer indexierten Audiodatei, die in der richtigen Reihenfolge abgespielt werden kann
Diese Pipeline ermöglicht eine freie und interaktive Kommunikation mit dem Chatbot. Sie erlaubt zudem:
- Die Integration von Befehlen, die der Bot direkt ausführen kann
- Die Einbindung von Retrieval-Augmented Generation (RAG), um Antworten auf Basis exakter Daten zu generieren
- Ein modulares Design, das den Austausch einzelner Komponenten oder KI-Modelle ermöglicht
Durch diese Architektur entsteht ein flexibles System, das über einfache textbasierte Chatbots hinausgeht und eine realistischere, interaktive und erweiterbare Mensch-KI-Interaktion ermöglicht.
Chatbot mit Sprechblase
Zur Verbesserung der Barrierefreiheit in VR wird die gesprochene Antwort des Chatbots zusätzlich als Text in einer Sprechblase dargestellt. Dies hilft Nutzern mit Hörbeeinträchtigungen und ermöglicht eine bessere Verständlichkeit, insbesondere in lauten Umgebungen oder bei undeutlicher Sprachausgabe.

Ergebnisse
Zur Validierung der Pipeline wurden Nutzertests durchgeführt. Die Hauptziele dabei waren:
- Bewertung der Performance meiner Pipeline im Vergleich zu anderen Chatbots
- Erfassung von Verbesserungsvorschlägen
- Sammlung von Ideen für weitere Anwendungsfälle
Für die Tests wurden drei verschiedene Use Cases in einer VR-Umgebung entwickelt:
- Interview-Trainer: Ein virtueller Gesprächspartner zur Simulation von Bewerbungsgesprächen
- Memory-Bot: Ein Chatbot, der sich effektiv Nutzerdaten merkt und in Gesprächen wiederverwendet
- Mülltrennungs-Helfer: Ein Assistent, der auf lokale Richtlinien zur Mülltrennung zugreift und korrekte Anweisungen gibt
Mülltrennungs-Bot
Der Chatbot unterstützt Nutzer dabei, Abfälle korrekt zu trennen. In der Szene befindet sich auf der linken Seite ein Plakat mit Richtlinien zur Mülltrennung, um den Testpersonen eine Referenz zu bieten. Darunter stehen verschiedene Mülleimer für Altpapier, Biomüll, die Gelbe Tonne und Restmüll. Auf der rechten Seite liegen problematische Gegenstände, die der Nutzer dem Bot zuordnen kann.

Zur Evaluation wurden zwölf Testpersonen eingeladen, die mit den Chatbots interagierten. Anschließend füllten sie für jeden Bot den BUS-11 (Chatbot Usability Scale) Fragebogen aus. Zusätzlich wurden nach den Tests Interviews durchgeführt, um qualitative Rückmeldungen zu erhalten.
Haupterkenntnisse aus den Tests:
- Obwohl die Animationen der Avatare nicht im Fokus der Entwicklung standen, war der häufigste Kritikpunkt, dass die Chatbots als „zu robotisch, unnatürlich oder sogar unheimlich“ empfunden wurden. Dies zeigt, dass in VR-Umgebungen die Erwartung an Natürlichkeit deutlich höher liegt als bei textbasierten Chatbots auf Websites.
- Der BUS-11-Fragebogen erwies sich als nur bedingt geeignet für VR-Umgebungen. Einige Fragen, wie z. B. „Der Chatbot war leicht zu finden“, erhalten in einem immersiven Setting eine völlig neue Bedeutung.
- Durch Optimierungen kann die Antwortzeit erheblich reduziert werden. Mögliche Ansätze hierfür sind:
- Streaming von Input/Output zwischen verschiedenen Modellen
- Aufteilung der LLM-Antwort in einzelne Sätze, um die Verarbeitung durch STT parallel zu beschleunigen
- Optimierung der Betonung im TTS, sodass sie innerhalb eines Satzes natürlich bleibt
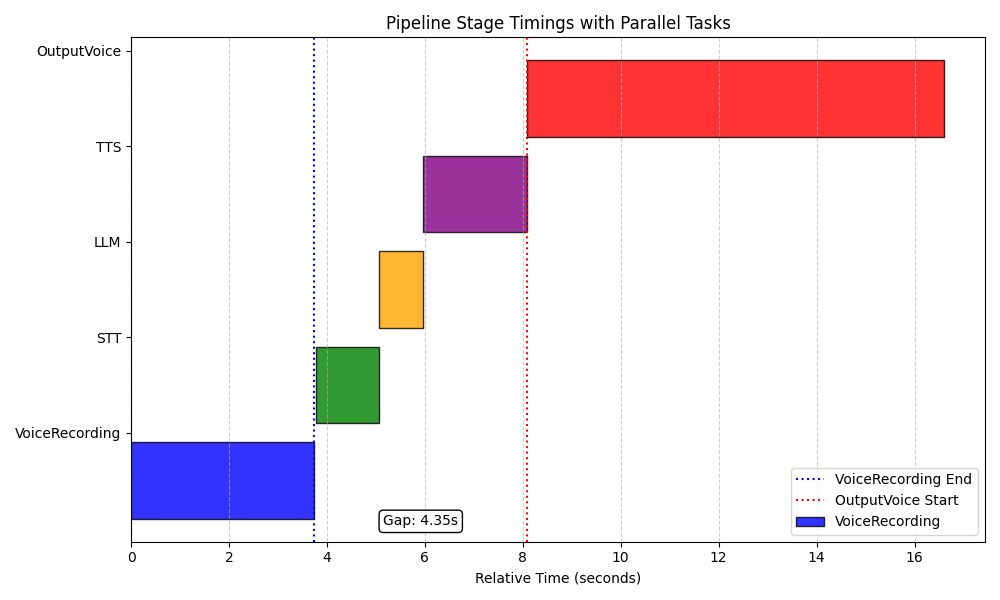
Diese Grafik zeigt die Antwortzeiten einer nicht optimierten AI-Pipeline. Jeder Verarbeitungsstufe startet erst, nachdem die vorherige vollständig abgeschlossen ist, was zu längeren Wartezeiten führt.
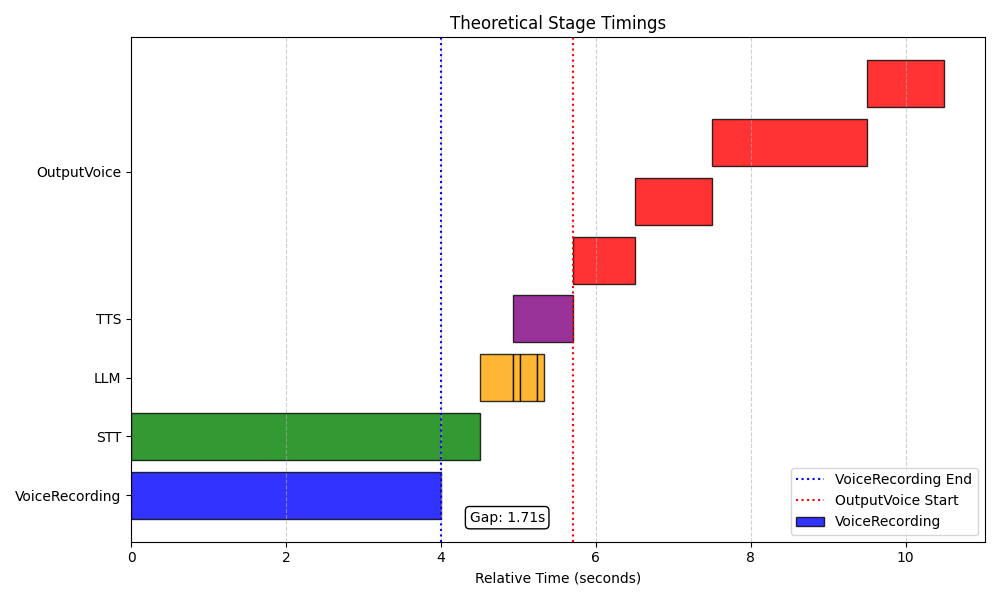
Diese Grafik zeigt die Antwortzeiten einer optimierten AI-Pipeline. Durch Live-Transkription wird bereits während der Eingabe Zeit eingespart. Zusätzlich wird die Antwort des LLMs in Echtzeit gestreamt und in einzelne Sätze unterteilt, sodass der Bot früher reagieren kann.
Fazit
Die entwickelte Pipeline hat meine Erwartungen übertroffen, da es nicht notwendig war, separate Pipelines für die verschiedenen Use Cases zu erstellen. Die modulare Struktur erwies sich als flexibel und anpassungsfähig für unterschiedliche Anwendungen.
Weitere Forschung sollte sich verstärkt auf die Natürlichkeit und Glaubwürdigkeit der Avatare konzentrieren, da dies in immersiven Umgebungen eine zentrale Rolle für die Benutzererfahrung spielt. Zudem sind neue Evaluationsmethoden erforderlich, um multimodale KI-Systeme in verschiedenen Medien wie VR und AR besser zu bewerten.
Einsatz von KI
In meiner Arbeit habe ich bewusst KI-Tools wie GPT und DeepL genutzt, um eine umfangreiche und gut lesbare englische Abhandlung zu verfassen. Ich habe diesen Einsatz offen kommuniziert und bestätige hier nochmals, dass sämtliche Forschung und Inhalte von mir stammen. KI wurde ausschließlich zur Verbesserung der Lesbarkeit und zur sprachlichen Optimierung verwendet.
KI hat keine Inhalte „frei generiert“, sondern lediglich Vorschläge gemacht, die ich nach eigener Recherche gegebenenfalls in meine Rohfassung übernommen habe. Der Umfang dieser Arbeit wäre ohne diese Tools erheblich schwerer zu bewältigen gewesen. Ich bin der Überzeugung, dass genau darin der Mehrwert solcher Werkzeuge liegt – sie ermöglichen es, sich stärker auf die wissenschaftliche Arbeit zu konzentrieren, anstatt sich mit der reinen Formulierung von Sätzen aufzuhalten.